
之前在初识 AI Infra 中,我基于自己的调研和有限的实习经历,写下了对这个方向的初步认识:核心命题是什么、和应用开发有什么区别、为什么选它、以及可能的风险。
最近又和两位朋友分别深聊了一次。一位是工业界的朋友,目前在头部大厂做 AI Infra,之前做过传统 Infra,近期转到了 AI Infra;另一位是同校的博士学长,方向是算子开发。两个人的背景完全不同,但聊完之后我发现,他们对很多问题的判断出奇地一致,同时也有些有趣的分歧。
本文主要分享一下我们讨论的部分问题、他们的观点、以及我的一些看法。由于样本数也比较少,本文只能算是访谈复盘,无法代表整个工业界或学术界的看法,需要辩证看待。如果你也在考虑要不要做 AI Infra,或者对这个方向好奇,希望能有一点参考价值。
为什么是 AI Infra
工业界的朋友觉得 AI Infra 的角色是整个 AI 产业链的”效率因子”——它不直接产出模型,但能显著提升模型迭代的效率、降低训练和使用模型的成本。在他看来,目前 AI 领域有三大值得关注的方向:基模、数据和 AI Infra。其中 AI Infra 是那个让前两者跑得更快的加速器。
同校学长的研究方向是存算一体,他选择做 AI Infra 也是因为看好这个领域的前景,而且做算子和他的研究方向不算冲突。他个人是古法编程的支持者,而目前 AI Infra 暂时还没有被 Vibe Coding 占领,虽然他也承认这种局面可能很快就会被打破,但 AI Infra 本身的难度和壁垒可见一斑。
从工业界到学术界,不同角度指向同一个判断:AI Infra 是目前少数既有足够技术深度、又有持续增长需求的方向之一。
我和他们有类似的判断,不过是从推导方式不太相同。我之前做过传统后端开发,也做过当前非常流行 Agent,我觉得这些工作没有本质区别——说白了都是写业务代码。Vibe Coding 的出现让这个问题更加尖锐:一个本科生只要用上 Claude Code,就能在短时间内上手大部分后端和 Agent 开发。而我近期接触了一些 Infra 的工作后,感受很直接:AI Infra 不一样,光是推理框架就已经很有难度了,更别说训练和算子。这些门槛是能够实实在在构建出壁垒的。
之前在字节做后端时的部门业务就与 Infra 相关,虽然不是 AI 方向,但能感受到整个公司的重心在明显往 AI 倾斜。传统 Infra 很成熟,学习曲线平缓,而 AI Infra 还在快速演化中——这意味着机会,也意味着需要持续学习。
此外,我个人认为,相比做基模,能把 AI Infra 做到顶尖的人更少。有一句话我认为比较能支撑这个观点:”想教一个 Engineer 做 Research 会比较简单,但想教一个 Researcher 做 Engineering 会很难”。底层原因是 Researcher 对技术的深度要求很高,他们没有那么善于将自己的注意力分散到多个维度;而工程师解决问题通常是需要同时考虑多个维度的。而做 AI Infra 你需要在有多维度思考的能力的基础上,还需要能够深入各个角度,对知识的广度和深度都有比较高的要求。
这个领域到底在做什么
聊到 AI Infra 的技术全景时,工业界的朋友根据他的理解,给了一个很清晰的分层,大致可以用下图表示:
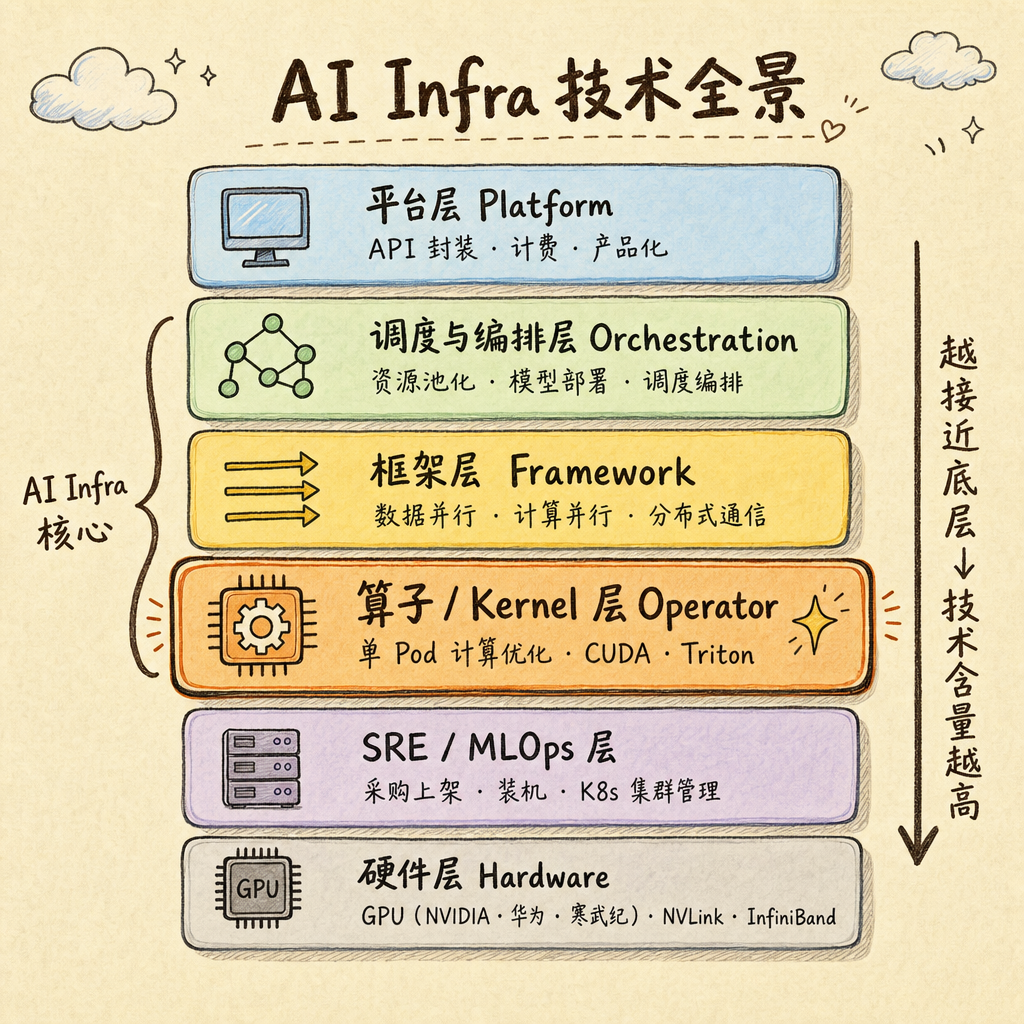
- 硬件层:通常做的是适配不同厂商的 GPU,比如英伟达、华为、寒武纪等
- SRE / MLOps 层:偏向运维方向,主要做采购、上架、装机、K8s 集群管理等
- 算子 / Kernel 层:一般是单个 Pod 内的具体计算优化,最接近硬件
- 框架层:需要解决数据并行、计算并行、分布式通信等问题
- 调度与编排层:实现资源池化,模型的部署、调度与编排,为上层提供便利
- 平台层:API 封装、计费,偏产品侧,可能会直接对接具体产品
在他看来,这些方向的价值排序大致是:Kernel > 框架 > 编排 > 产品 > SRE。越靠近底层、越接近计算本质的方向,技术含量越高,也越核心。
博士学长把这些粗略分成了三个赛道:
- 训推框架:对数学和竞赛功底要求高,有 ACM 金奖将会很加分
- 业务推理框架:特定场景的内存/通信/数据优化,以及分布式训推,需要对传统 Infra 有经验
- 算子开发:最底层的算子优化,对数学理论功底的要求很高,也需要熟悉各家硬件
两个人的分法不一样,但本质上描述的是同一片领域。如果说工业界的视角是”从公司组织架构看这条链路上有哪些团队”,学术界的视角就是”从一个想入行的人看有哪些方向可以选”。
行业走到哪了
这是我最好奇的问题之一。
工业界朋友的判断是一句话:没那么毛糙了,但还远不够精细化。AI 本身发展太快,业务需求变化大,Infra 层面来不及做深度的精细化优化。目前很多场景下,用简单策略就能带来很大的性能提升——这本身就说明行业还处于中早期,有大量的低垂果实可以摘。
我自己也预期 AI Infra 至少三到五年内还处于需求持续增长期,这和十五五的大战略方向是吻合的,AI Infra 可以说就是人工智能领域在计算机层面的“能源基础”,只不过能源基础设施带来的是更多的电,而 AI Infra 带来的是更多算力。
综合起来判断,画面就比较清楚了:这个领域还没到精耕细作的阶段,但已经过了最初的蛮荒期。 行业会向好,窗口还在;但对于想入场的人来说,窗口正在收窄。
Vibe Coding 会取代我们吗
这个话题很有意思,因为两个人的关注点完全不同。
我和学长聊的更多的是「Vibe Coding 替代了谁」。我们的共识很明确:后端开发和 Agent 开发已经被大幅降低了门槛,但 AI Infra 暂时还没有。推理框架、训练框架、算子优化——这些工作的复杂度不是 Vibe Coding 目前能处理的。选择 AI Infra,某种意义上是在选一个 AI 暂时够不着的方向。
工业界的朋友想的更远一步。他承认人目前仍然不可或缺,但认为人的角色会发生变化——不是被取代,而是需要更擅长使用 AI。AI Infra 的性能指标和优化需求持续随业务变化,天然不那么适合模型一揽子解决,但这不意味着 AI 永远做不到。近期通过 Agent 直接端到端解决 AI Infra 的研究越来越多,字节近期推出的 Cuda Agent 就是一个典型的案例。
我自己比较认同 Andrej Karpathy 的观点:凡是能够以某种方式被验证的问题,迟早能被 AI 自动化。Ion Stoica 的团队也在积极探索用 AI 自动化地提升系统整体性能。AI 或许不只是解决现有问题,更能做到以往人类无法做到的事情。但要实现这些,关键在于人更擅长使用 AI,而不是靠 AI 独立完成。
所以我的结论是:不要因为觉得 AI Infra”安全”就选它,要因为你对这个方向本身感兴趣,能够支撑你深挖这个领域。 安全感是暂时的,兴趣才能支撑你走远。
什么能力最重要
这个话题上,两个人的回答形成了有趣的互补。
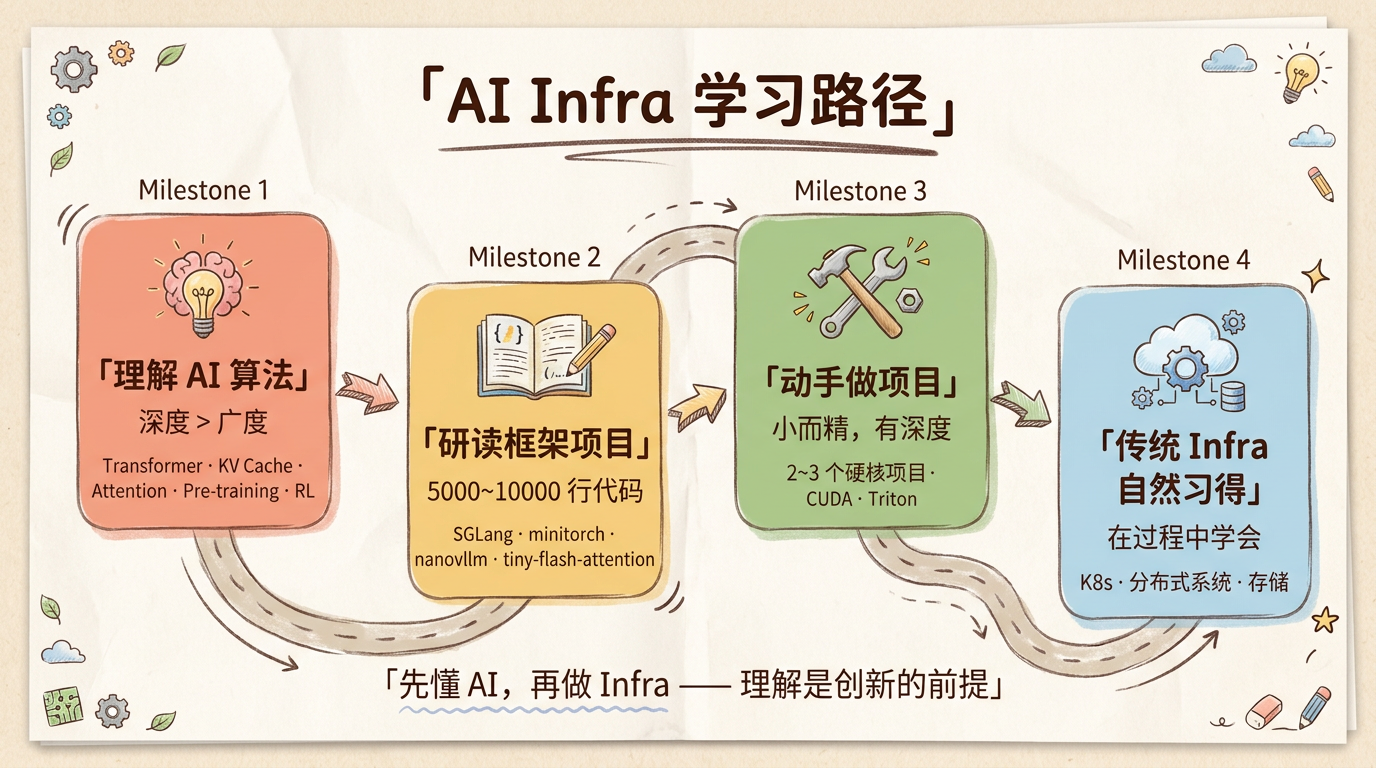
工业界的朋友非常强调一点:对 AI 的深入理解远比传统 Infra 技能重要。他举了很具体的例子——你得理解 Transformer 架构、KV Cache、Attention 机制这些底层原理,才有可能做出 KV Cache 优化、PagedAttention 这样的工程创新。做训练需要懂 Pre-training 的优化原理,做 Post-training 需要了解 RL。通俗来说:想做好 AI Infra,尤其要做到极致,对 AI 算法的理解必须足够深——不要求你在算法上有直接创新,但一定要有理解当前 SOTA 算法的能力。
而传统的 K8s、分布式系统这些?他觉得上手门槛不高,学就行了。
这个观点和我在网上看到的很多说法不一样。不少人认为 AI 只需要过一个入门门槛,重点在 Infra 本身。但我更认同他的看法:传统 Infra 已经非常成熟了,学习资源到处都是,而真正深入理解 AI 的人反而稀缺。
学长则从”怎么学”的角度补充了具体路径。他的建议是:找一个代码量在 5000 到 10000 行的训推框架项目来学习,比如 SGLang、minitorch、nanovllm、tiny-flash-attention 这些。通过研读这些项目,间接学会 CUDA、Triton 等底层工具。然后实现两到三个硬核项目——不需要大而全,小而精就行,有深度最重要。
两个人的建议放在一起,路径就比较清晰了:先建立对 AI 算法的深入理解,再通过具体项目把理解转化成工程能力。 传统 Infra 的技能可以在过程中自然习得,不需要刻意优先。
人才市场现在什么样
工业界的朋友说得很直白:极度缺人,每个方向都缺。人才流动性也不错,跳槽机会多。
但门槛在变化。2024 到 2025 年,有传统 Infra 经验的人还可以跨方向转入 AI Infra。到了 2026 年,对 AI 相关经验的要求明显提高了——不是说完全不要没有 AI 背景的人,但门槛确实高了不少。
晋升方面,相比传统研发方向,AI Infra 的机会多得多。用他的原话说——“机会简直太多了,简直就是机会本身”。
压力当然也不小。很卷,大家都很努力。
我自己近期在创业公司接触 AI Infra 后也有类似的感受——这个方向的 bar 明显比做业务要高很多。但也正因为如此,才有更大的发展空间。
创业公司适合做 AI Infra 吗
这个问题是我在和工业界朋友聊天时抛出来的,因为当时看到硅谷有不少 AI Infra 方向的 startup。
他不太看好。理由很朴素:AI Infra 是需求驱动的。没有明确的业务需求,很难做出好的 Infra。小公司没必要花大钱自建,老老实实用已有的服务做应用,效益最高。
聊完之后我也认同这个判断。Infra 恰恰是一个需要针对各家业务特化才容易优化的方向——你想做通用方案让所有人都用,不是技术上做不到,而是事实上很难让各家接受你的框架而舍弃已有建设。
我之前在字节时听过架构师的分享,他说我们可以参考 Meta、Google 的 Infra——它们确实更优秀,但没法直接照搬,因为已有建设差异太大,这是路线不同导致的。硅谷有 Databricks 这样的成功案例,但那是数据 Infra,赛道不完全一样。更多的 AI Infra startup,可能只是风口上的杂音。
要不要读博
这个话题主要是和博士学长聊的,但我觉得对很多在犹豫的人有参考价值。
他分享了一个很实在的判断标准:如果没有任何资源支持,你能不能靠自己的能力毕业? 要接受自己可能没有产出。没有好坏之分,只有适不适合。
他还提到了两种导师风格:一种偏美式,平时几乎不管,但要求产出,实验室竞争氛围很强;另一种偏国内传统,一个博士带一群硕士一起做。选导师本质上是在选一种你愿意接受的科研生活方式。
对我来说,这段对话让我更加确认了一件事:不管最终选不选读博,最重要的是先把技术实力建立起来。方向选对了,路径可以再调整。
写在最后
两场对话,两个完全不同背景的人,但聊完之后拼出来的图景比任何一方单独描述的都要完整。
工业界的朋友让我看到了 AI Infra 在实际生产环境中的复杂度和价值排序——什么方向最核心、什么能力最稀缺、行业发展到了哪个阶段。博士学长让我看到了一条从零开始的学习路径——怎么选方向、怎么建项目、怎么积累到足以入场的能力。
相比初识时的认知,这两场对话让我有了一些新的理解:对 AI 算法的深入理解比传统 Infra 技能更重要、行业还处在有大量低垂果实可摘的中早期、以及不要因为”安全”选 AI Infra,而要因为兴趣。尤其是最后一点——初识时我更多是从「壁垒」和「不容易被替代」的角度看问题,现在觉得那只是起点,真正能走远的还是对这个方向本身的热情。
如果把这些浓缩成一句话,大概是:
AI Infra 的窗口还在,但正在从”敢转就行”变成”得有真东西”。 理解 AI 的深度、动手做项目的密度、以及持续学习的耐心——这三样东西,比任何学历或标签都重要。
我自己也还在路上。写这篇文章的过程,也是在整理自己的思路。希望下次再写 AI Infra 相关的内容时,我已经不只是在聊别人告诉我的事,而是在分享自己做出来的东西。
