
承接 初识 AI Infra 里的方向判断,下面是在 Claude 的帮助下、根据现有资料整理的一套学习路线,作为接下来研究生生涯的粗粒度计划。
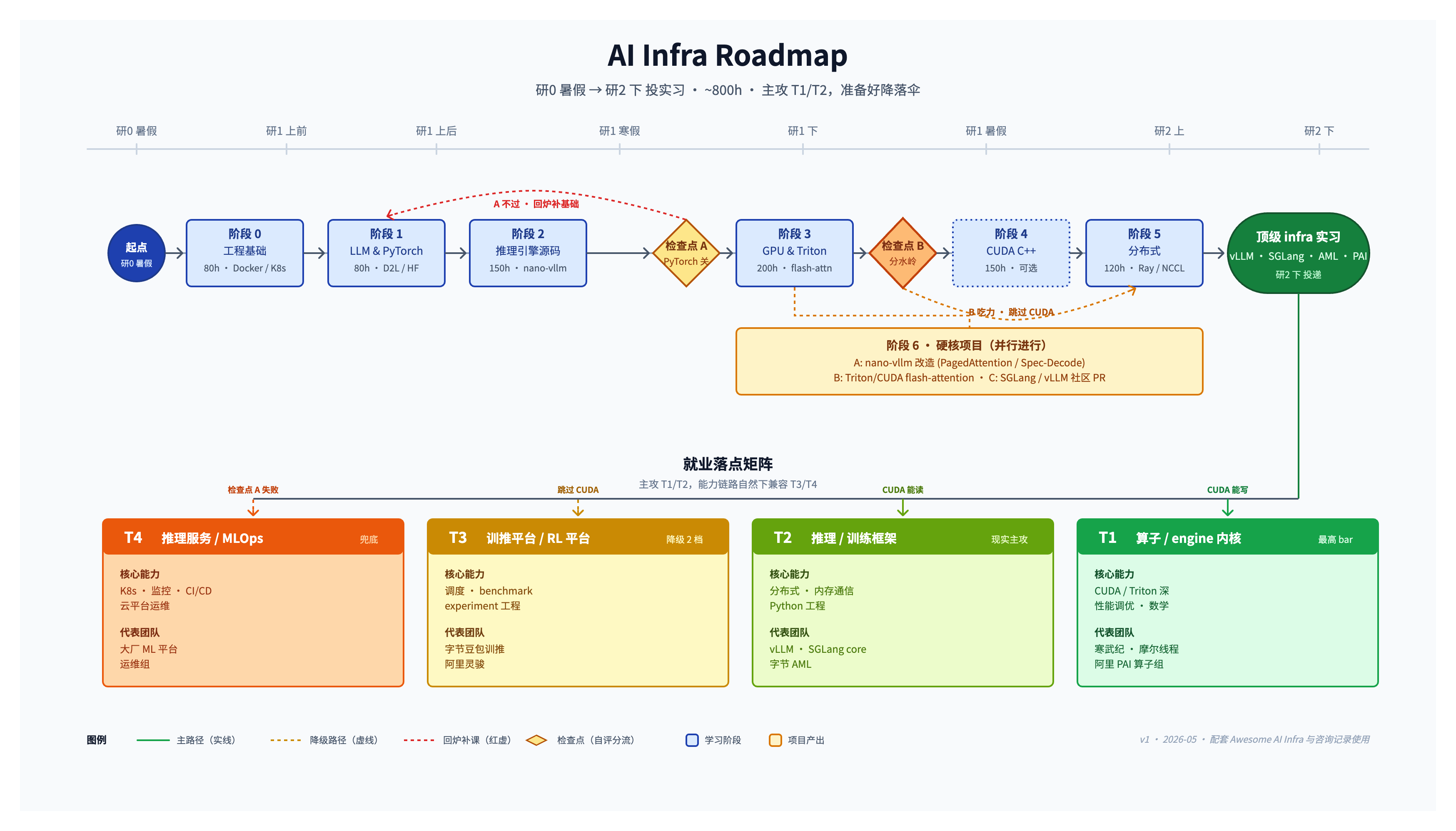
整条路线大约 800 小时,分六个学习阶段,阶段 6 的项目实践从阶段 3 起就并行推进。
TIP这条路线是按知识依赖排出来的理想顺序,并不要求线性学完。对于有一定基础的科班同学来说,直接上项目、用项目反向驱动自己补技术,往往比按部就班学完前置更快。
阶段 0:工程基础(约 80h)
目标:能跑通推理框架的容器化部署,能 debug。
- Linux / shell / 网络基础(够用即可)
- Docker(必须熟练)
- K8s 基础概念:Pod / Service / Deployment(看懂 yaml + kubectl logs 即可,不深入)
暂时不需要学:MLflow、DVC、Airflow、Terraform、云平台细节。
阶段 1:LLM 与 PyTorch 强化(约 80h)
目标:能讲清楚 LLM inference 一个 token 是怎么生成的。
- D2L 重读 Attention / Transformer 章节
- HuggingFace transformers + PyTorch 用熟
- LLM inference 流程:prefill / decode / KV cache
阶段 2:推理引擎——从用户侧到源码侧(约 150h)
推理(Inference) 是模型上线之后的事,目标是延迟低、吞吐高、显存省。优化点非常密集——KV cache、speculative decoding、continuous batching、量化,这些都是推理框架在卷的方向。代表项目:vLLM、SGLang。
这一阶段的目标:能讲清楚 vLLM 为什么比 HF generate 快。
- vLLM 部署调参 benchmark
- 啃 nano-vllm 源码(约 5k 行,把核心逻辑抽出来的极简实现)
- 核心概念:PagedAttention / continuous batching / TP / PP / EP
这一阶段还不碰 CUDA。
阶段 3:GPU 与 Triton(约 200h)
算子(Kernel) 负责把 PyTorch 这种高层 op 映射到 GPU 上的具体代码;编译器(Compiler) 则更进一步做图优化和算子融合。编译器太硬核,入门先专注算子层面。
这一阶段的目标:能用 Triton 实现并优化 GEMM / softmax / flash-attn-mini。
- GPU 体系结构:SM / warp / memory hierarchy
- Triton 优先(比 CUDA 上手快,适合先建立 kernel 编程的直觉)
- 实现顺序:Triton GEMM → softmax → flash-attn 简版
阶段 4:CUDA C++ 入门(约 150h,可选)
目标:能读懂 vLLM / SGLang 的 kernel 代码并做小修小补。
- CUDA 基础语法、内存模型、cuBLAS / cuDNN
- 读 cccl / cub 的一两个 kernel
- 把阶段 3 的 Triton kernel 重写为 CUDA 版做对比
走算子方向的必经之路;走推理框架上层的话,能读懂即可。
阶段 5:分布式(约 120h)
预训练(Pre-Training) 的核心矛盾是把任务切到上千张卡同时压低通信成本;后训练(Post-Training,SFT / RLHF / DPO) 则在预训练基础上贴自家数据。这两块都需要扎实的分布式基础。代表框架:DeepSpeed、FSDP、Megatron-LM。
这一阶段的目标:跑通 single-machine multi-GPU 的训练 / 推理 demo。
- Ray 核心
- NCCL / 集体通信
- DeepSpeed / Megatron 的 single-node multi-GPU demo
- 分布式范式:DP / TP / PP / EP / SP
阶段 6:项目实践(持续,与阶段 3+ 并行)
光跑通示例不够,需要有拿得出手的项目。建议 2~3 个,小而精,有深度:
- 推理 engine:改造 nano-vllm,加 PagedAttention 或 speculative decoding
- 算子:Triton / CUDA 版 flash-attention,benchmark 对比 PyTorch SDPA
- 社区贡献:给 SGLang / vLLM 提非 trivial 的 PR
每个项目的交付标准:可运行代码 + benchmark 报告 + 技术博客一篇。
